

In natural language processing, the state of the art is dominated by large Transformer models, which pose production challenges due to their size.
The 1.5 billion parameter GPT-2, for example, is ~6 GB fully trained, and requires GPUs for anything close to realtime latency. Google’s T5 has 11 billion parameters. Microsoft’s Turing-NLG has 17 billion. GPT-3 has 153 billion parameters .
For more context, I’d recommend Nick Walton’s write up regarding the challenges of scaling AI Dungeon, which serves realtime inference from a fine-tuned GPT-2.
Because of these challenges, model optimization is now a prime focus for machine learning engineers. Figuring out how to make these models smaller and faster is prerequisite to making them widely usable.
In this piece, I’m going to walk through a process for optimizing and deploying Transformer models using Hugging Face’s Transformers, ONNX, and Cortex. For comparison, I’ll be deploying both a vanilla pre-trained PyTorch BERT and an optimized ONNX version as APIs on AWS.
Optimizing a Transformer model with Hugging Face and ONNX
We’ll start by accessing a pre-trained BERT and converting it to ONNX. Why are we converting BERT from PyTorch to ONNX? For two reasons:
- ONNX Runtime’s built-in graph optimizations accelerate Transformer inference better than other popular optimizers, according to benchmarks.
- ONNX Runtime is capable of more efficient quantization (reducing the size of a model by converting it to integers from floating point decimals).
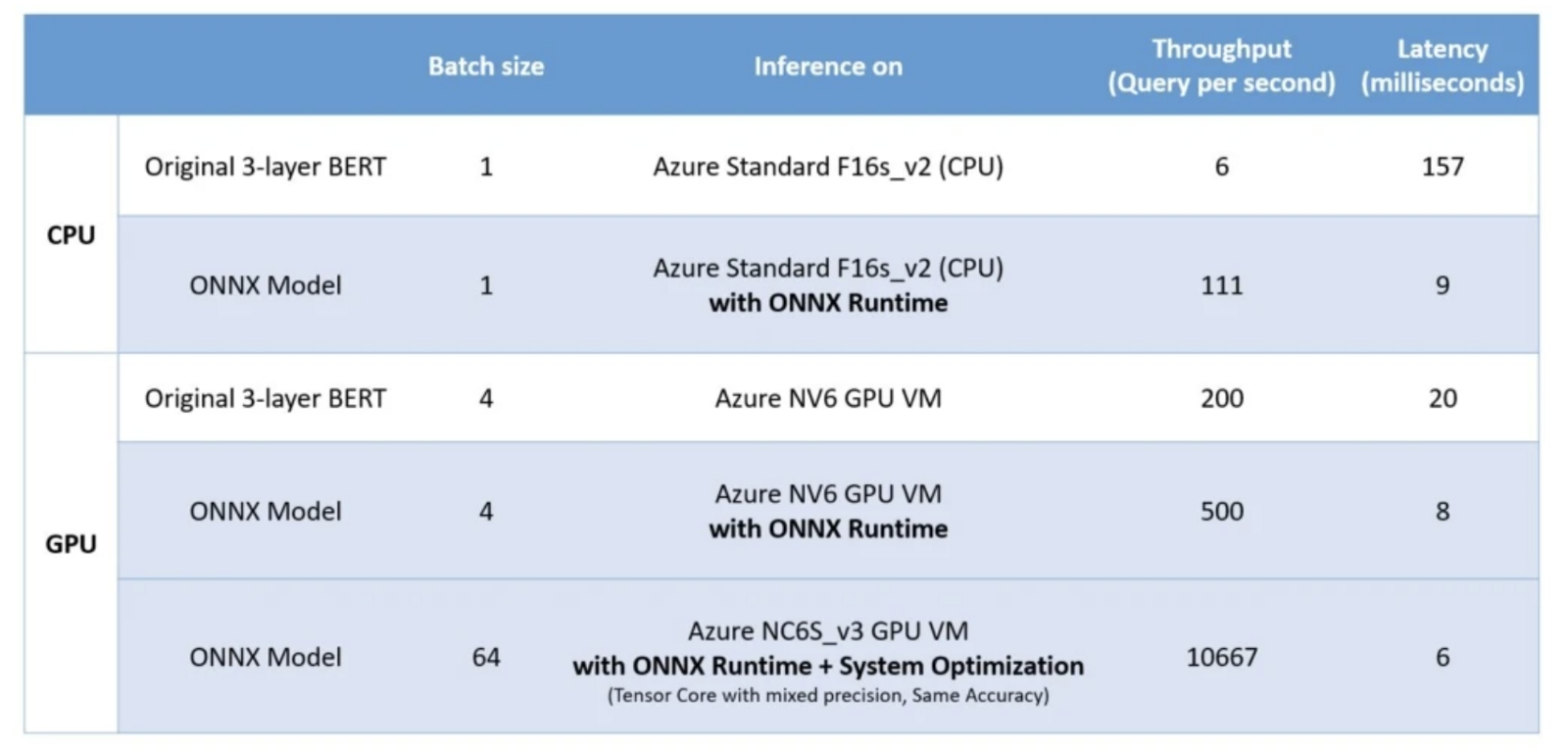
According to data released by Microsoft, they saw a 17x increase in CPU inference by optimizing the original 3 layer BERT in ONNX.
Actually performing the optimization is pretty straightforward. Hugging Face and ONNX have command line tools for accessing pre-trained models and optimizing them. We can do it all in a single command:
.png)
With that one command, we have downloaded a pre-trained BERT, converted it to ONNX, quantized it, and optimized it for inference.
Quickly comparing the size of the two models after our ONNX model has been quantized:
- PyTorch: 417 MB
- ONNX: 106 MB
That’s roughly a 4x size reduction out of the gate. Encouraging, but let’s see how this impacts inference speed.
Serving ONNX and Pytorch models locally
Now that we have an optimized model, we want to serve it. For our purposes, this means wrapping it in a prediction API.
Note: We’re using Cortex for deployment here. It should be easy to follow along if you’re unfamiliar with the platform, but in case anything is too unfamiliar, you can reference the documentation here.
This is our PyTorch prediction API, which initializes a pre-trained BERT using the Transformers library and defines a predict() method for it:
Our ONNX API will use the same basic logic:
Once deployed, we can send some test traffic to both APIs, and check their performance via the Cortex CLI:
.png)
While our PyTorch model averages 1.19756 seconds per request, our ONNX model performs at 159.708 milliseconds per request — an almost exactly 7.5x increase in inference speed.
And, keep in mind, these are just being deployed to my not-top-of-the-line MacBook. Deployed to a production cluster, which we can do in just a few commands with Cortex, these models would perform significantly faster.
Deploying ONNX Runtime to production
Now we want to see how these models perform in production. To test, I’ve spun up a quick Cortex cluster and deployed the APIs to the cloud.
Currently, these APIs are running on c5n.xlarge instances, which use threads on an Intel Xeon Platinum 8000. After sending some traffic to each API, we can compare their performance here:
.png)
The speed up is even more extreme here — our ONNX model increased speed more than 10x .
Final results
At the end, our optimized ONNX model is:
- 4x smaller than on PyTorch
- 10x faster than on PyTorch
That's a potential 40x increase in inference throughput.
To put these numbers in a bit more perspective, think about it from a cost perspective. Cortex, for example, uses request-based autoscaling to scale up prediction APIs. At a very high level, this means that Cortex calculates the number of instances needed by comparing the length of the request queue against the concurrency capabilities of a single API.
Let’s say that shrinking the model by 4x allows us to fit 3 more APIs on a single instance, and that speeding up inference by a factor of 10 allows each model to handle 5 times as many concurrent requests (this is a conservative estimate). If you currently maintain an average of 25 instances to handle production traffic, these optimizations would bring your instance count down to 2.
If an instance costs $0.80 an hour, you’ve gone from spending $175,200 per year to spending $14,016 — a number you could reduce by another roughly 50% by deploying on spot instances.
Most Transformer models can be optimized and deployed along these same lines using ONNX Runtime and Cortex. For more details on optimization, check out the ONNX team’s write up of the process.
.jpg)