We're joining Databricks! Read the announcement here.
Deploy, manage, and scale machine learning models in production.
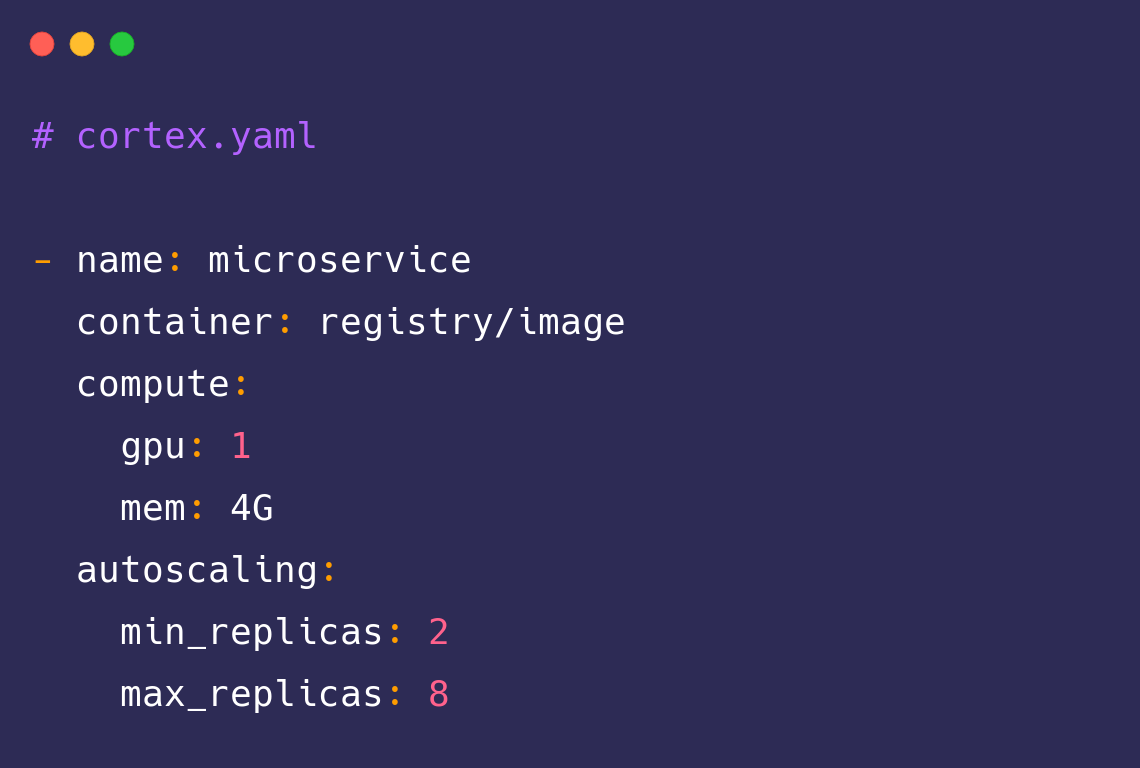
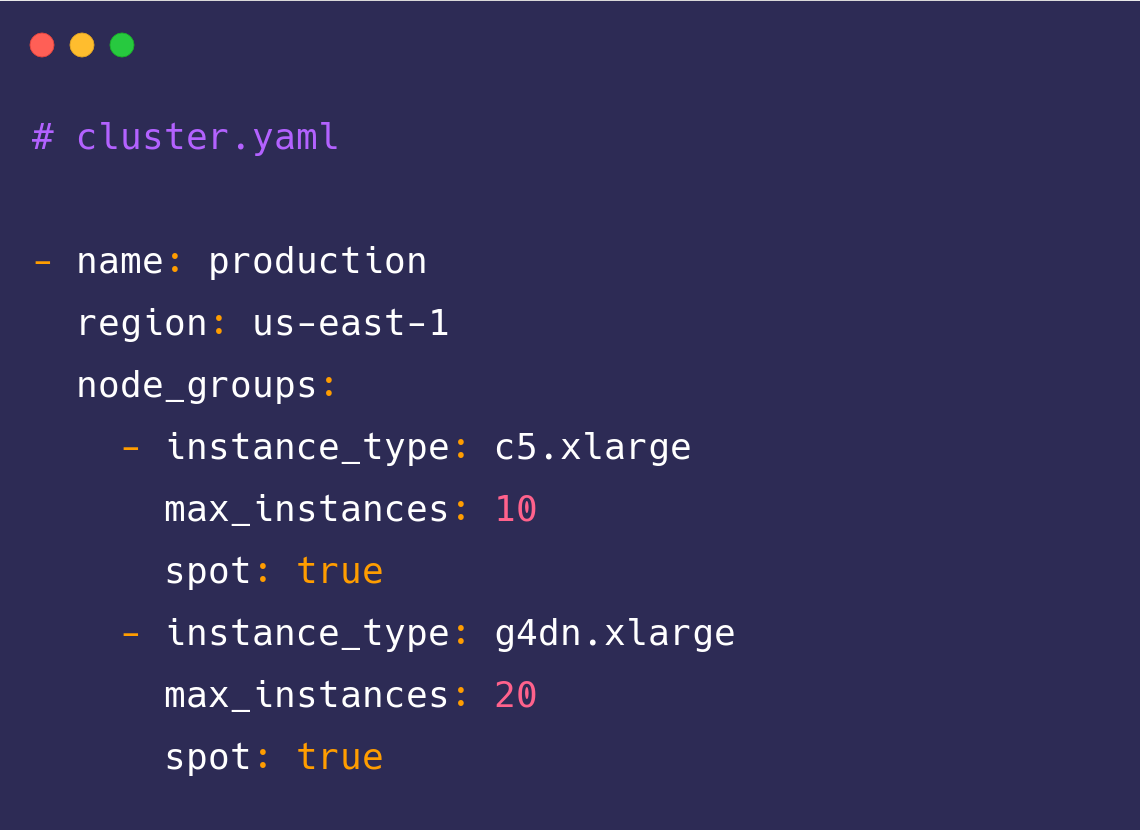


Discovering Cortex has been a lifesaver, it is servicing half a billion API calls each month for us. The ease with which we’ve been able to deploy Cortex has facilitated rapid development across our team, enabling us to meet the needs of our highly demanding customers.
