
In a recent article, a16z partners Martin Casado and Matt Bornstein laid out some of the differences they’ve seen between AI businesses and traditional software companies. Chief among these differences were expenses.
AI startups, according to the authors, spend more on cloud infrastructure, lowering their margins. Working on Cortex, we’ve seen the same pattern.
However, we’ve also seen that this is not a terminal state. The high infrastructure costs of production machine learning are not an inevitable feature of machine learning, but are an effect of the current ML ecosystem.
In fact, there is a lot that can be done right now to lower the infrastructure costs of production machine learning and improve ML native companies’ margins, so much so that they approach those of traditional software.
What is an ML native business—and why are its margins bad?
“ML native” is a term we use to refer to businesses whose core product relies on, as opposed to simply being enhanced by, machine learning.
For example, Glisten.ai is an ML native startup whose core product is an API that takes product images and text, and classifies them according to a hierarchical taxonomy:
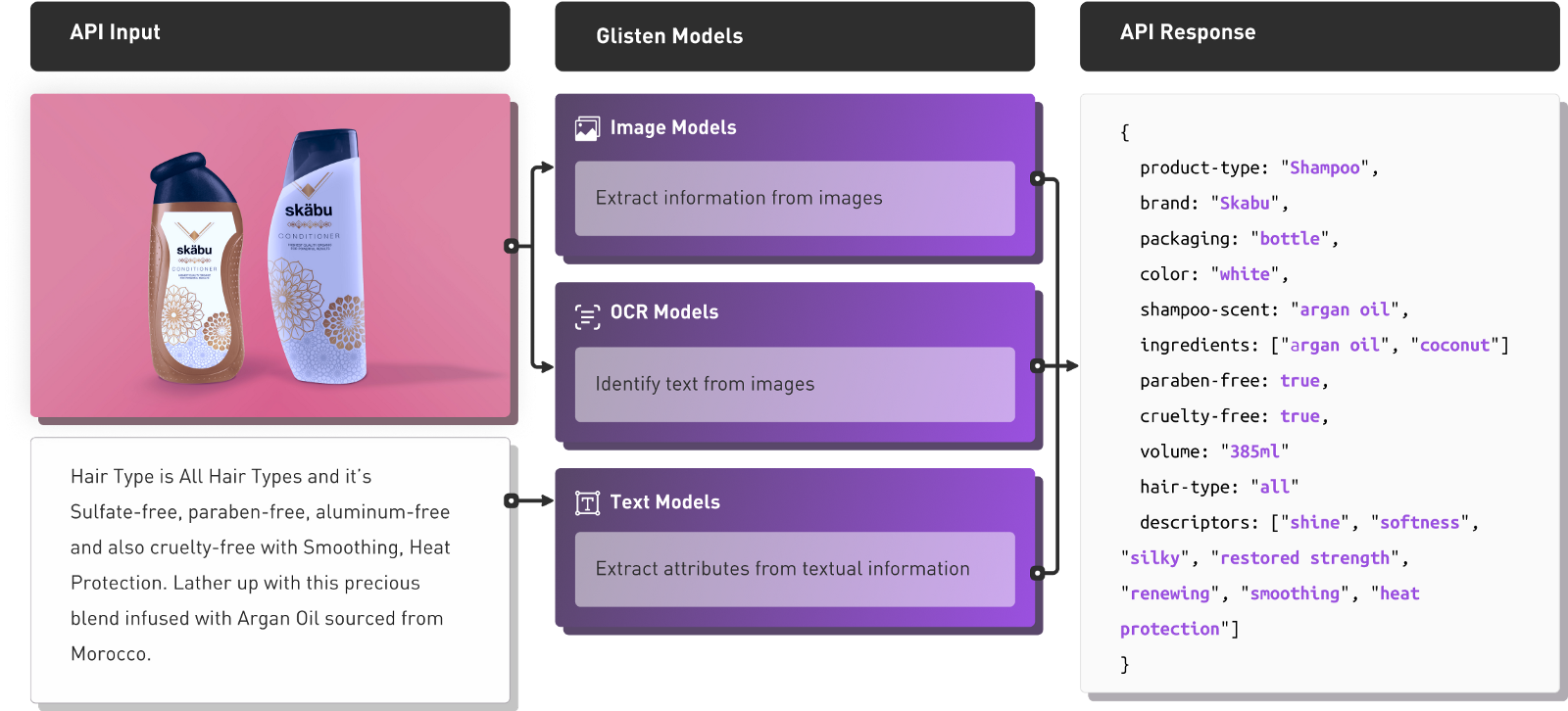
This solves a major problem for retailers who previously had to manually process huge volumes of products from different suppliers, most of which does not follow a particular standard for structuring product information.
While this is a tightly scoped, widespread business problem—the kind we’re used to seeing traditional software companies gobble up—it is also one that can only truly be “solved” by inference. Without machine learning, the product doesn’t exist.
That’s certainly an exciting prospect, but only if the margins are right. Unfortunately, for many ML startups, the margins are not right, mostly due to infrastructure costs. But why do ML startups have higher infrastructure costs?
Compute spend, mostly.
Simply put, serving a model in production requires significant compute resources. To use a somewhat dramatic example, take a large Transformer model like GPT-2:
- GPT-2 is large. At nearly 6 GB fully trained, GPT-2 is larger than most complete web apps. Due to its size, you can’t fit many copies of GPT-2 on a single server, which is particularly problematic given that…
- GPT-2 has a low concurrency threshold. Given its size and complexity, GPT-2 is not very performant. A single GPT-2 can only handle a few (if that many) concurrent requests.
- GPT-2 needs powerful compute resources. Related to the previous problem, if you want to serve GPT-2 with anything approaching realtime latency, you need to use GPUs, which are significantly more expensive.
In summary, if you deploy an ML native application built on GPT-2, such as AI Dungeon, even a small number of users will require you to pay for many GPU instances.
An app like Trello can offer a free tier because thousands of users are relatively cheap to handle. The average CRUD app can scale to thousands of concurrent users without breaking out of free tier services.
For ML startups, there is a high price to infrastructure out of the gate.
This situation, however, isn’t unavoidable. The core problem isn’t that machine learning is inescapably expensive. The real issue is that the production ML ecosystem is still young, and that there aren’t many infrastructure platforms built specifically for production machine learning.
Lowering the cost of machine learning infrastructure
The pathways to lowering the cost of machine learning infrastructure are fairly self-evident:
- Use more cost-effective compute resources
- Allocate compute resources more efficiently
And while on the surface this sounds like a problem the DevOps ecosystem has mostly solved, machine learning is just different enough to make traditional DevOps tools a poor fit.
However, while machine learning poses unique infrastructure challenges, it also opens the door to some unique opportunities for optimization.
For example, almost all models can be deployed on Spot instances, which are unused instances AWS sells at a steep (roughly 50% on average) discount. The tradeoff for traditional software is that Spot instances can be recalled without notice. But in machine learning, inference is a read-only operation, meaning losing state isn’t a concern. So long as your infrastructure platform can gracefully handle failover, recalled Spot instances aren’t an issue.
Enabling Spot deployments in Cortex cut many users AWS bills in half.
There are a number of similar ML-specific optimizations we’ve been able to implement, or are planning on implementing, that have widened the margins for ML native companies:
- Autoscaling. Standard autoscalers scale according to the resource utilization of an instance. However, because multiple models can fit on an instance, and because each model can have its own usage rate, compute needs, and concurrency threshold, we’ve significantly increased efficiency by scaling each individual model according to their request queue length.
- Multi-model caching. Availability is a pain point for ML native startups. A translation product may have 100s of models for different languages, all of which need to be available for inference. By allowing individual APIs to download and cache different models on demand, we’ve made availability significantly less of an issue.
- GPU sharing. The ability to dynamically allocate fractional GPUs significantly reduces the cost of GPU inference. We’re still working on implementing this one, but we expect it will make a big impact, particularly on companies deploying larger deep learning models.
With all of these optimizations, its not uncommon for an ML native startup to reduce their infrastructure costs by over 90%, putting them much closer to the margins of a traditional software company.
ML native is the next evolution of SaaS
A good deal of the low hanging fruit in SaaS—those tightly scoped, widespread pain points that can be automated away by traditional software—have been pounced on over the last 15 years. And while there will always be new pain points to solve and innovative products that steal markets, many of the Twilio-level, glaring opportunities have been seized.
There is, however, an entire world of problems that are not solvable by traditional, deterministic software. As commonplace as the feature is, nearly every company with ETA prediction in their app (Maps, Uber, Instacart, etc.) is solving the problem with a machine learning system they built in-house.
This is true for many other pain points. Fraud detection, translation, transcription, community monitoring, even drug discovery—all of these problems are commonly solved by machine learning, and implemented in-house, from scratch.
This is the opportunity ML native startups are seizing, and it’s identical to what SaaS businesses began doing 15 years ago. What Mailchimp did to email, PostEra is doing to medicinal chemistry. What Trello did to project management, Glisten is doing to inventory processing.
The big question is can we keep the infrastructure costs low enough to mirror the margins of traditional SaaS companies? If we can, there’s reason to believe that the next 15 years of SaaS will be defined by ML native startups.
.jpg)